
Category: Paper
-
How to Train Your Deep Research Agent? Prompt, Reward, and Policy Optimization in Search-R1
ref: https://arxiv.org/pdf/2602.19526v1 Summary I used to think longer prompts and step-by-step reasoning always make AI smarter. In daily use, that often helps. But in reinforcement learning, the opposite can happen. Researchers found that forcing models to “think” longer actually reduced accuracy and even caused training collapse. Some models learned to avoid answering questions entirely because…
-
Prompt Repetition Improves Non-Reasoning LLMs

ref: https://arxiv.org/pdf/2512.14982 Summary The easiest AI upgrade might be just “copy and paste”. Google researchers tested with 7 leading models and found that repeating the exact same prompt boosted results in 47/70 tests, with 0 losses! On one particular task, accuracy jumped from 21% to 97%. Even better, response time and output length stayed the…
-
Verbalized Sampling: How to mitigate Mode Collapse and unlock LLM diversity
ref: https://arxiv.org/pdf/2510.01171 Summary AI models repeat safe answers, but a simple prompt tweak can unlock far better thinking. Researchers introduced “verbalized sampling,” where the model lists possible answers (with score), explains which seems most likely and finally choosing. This pushes the model to explore instead of defaulting to familiar patterns. The result: up to 1.8x…
-
Tool-MAD: A Multi-Agent Debate Framework for Fact Verification with Diverse Tool Augmentation and Adaptive Retrieval
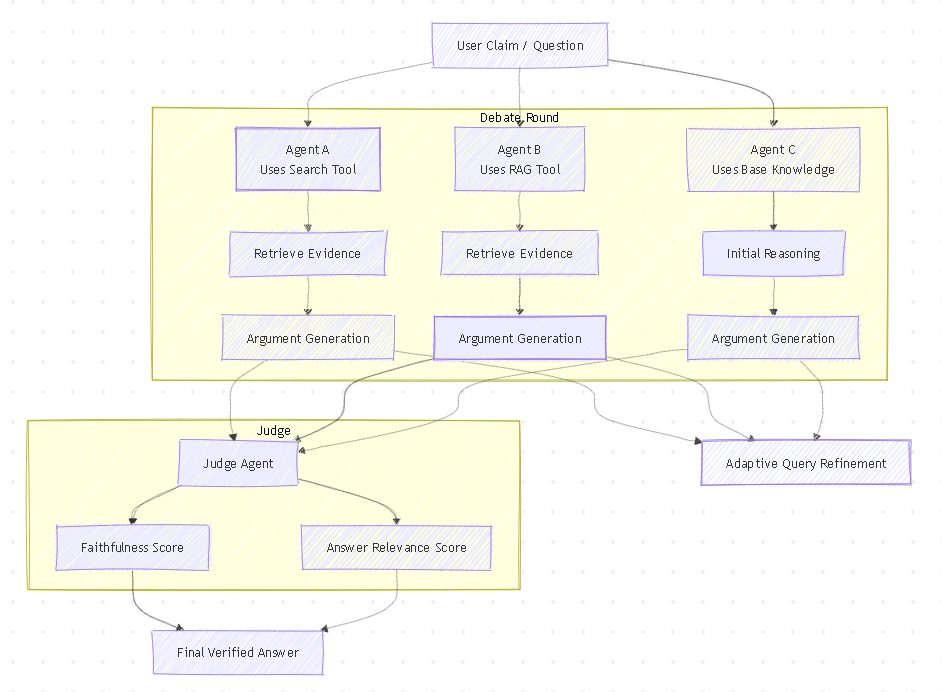
ref: https://arxiv.org/pdf/2601.04742 Summary The team studied several methods to improve LLM accuracy and combined the strongest ideas to build Tool-MAD. The system uses evolving AI debaters that run new searches in every round, refining queries based on the discussion to gather better evidence over time. A judge agent then evaluates the arguments using faithfulness and…
-
Small or Large? Zero-Shot or Finetuned? Guiding Language Model Choice for Specialized Applications in Healthcare

ref: https://arxiv.org/pdf/2504.21191 Summary The paper shows that finetuning still matters more than model size for well-defined tasks. The authors compared focused models (SLM + Fine Tune) and large models (LLM) across three scenario: basic binary classification, multi-class labeling, and multi-class with very minimal training data. Focused models trained with domain data consistently performed well, and…
-
SLMFix: Leveraging Small Language Models for error fixing with Reinforcement Learning
ref: https://arxiv.org/pdf/2511.19422 Summary The paper suggest to train small language model (SLM) repair code for least known programming languages. The report over 95% static-validation pass rate and improvements over direct LLM fine-tuning and self-correction prompting (agentic frameworks). The paper include building training pairs from LLM-generated programs, applies LoRA for initialization, then PPO reinforcement learning with…
-
Agint: Agentic Graph Compilation for Software Engineering Agents

ref: https://arxiv.org/pdf/2509.00625 webpage: https://www.agintai.com/ Summary Agint differs from workflow agents as a compiler agent (like IDE). It translates natural language into an executable, result-oriented DAG, where operating at the graph level enables parallel execution and removes the constraint of linear, chain-based generation. This approach emphasizes result-oriented execution: workflows are not fixed upfront but are dynamically…
-
NetGent: Agent-Based Automation of Network Application Workflows

ref: https://arxiv.org/pdf/2509.00625 github: https://github.com/SNL-UCSB/netgent Summary The paper introduces a state machine logic, similar to how games operate, into the field of UI automation. It compiles natural language into reusable, iterative states, where each state uses LLM-based reasoning for action selection and execution. This approach extends ReAct by adding explicit state memory and caching (compile-then-replay), reducing…
-
Needle in the Web: A Benchmark for Retrieving Targeted Web Pages inthe Wild
ref: https://arxiv.org/pdf/2512.16553 github: https://github.com/Tango-Whiskyman/Needle_in_the_Web Summary Needle in the Web explores a new benchmark for evaluating LLM search agents. It uses a broadcast + parallel retrieval approach (fuzzy exploratory search) instead of traditional multi-hop reasoning. Retrieved webpages are verified to ensure all query criteria are satisfied using single source, selecting a “ground-truth” page for answer generation.…
-
ScreenAgent : A Vision Language Model-driven Computer Control Agent
ref: https://arxiv.org/pdf/2402.07945 github: https://github.com/niuzaisheng/ScreenAgent Summary Performed end2end LLM agent development by constructing a real desktop interaction environment through VNC, enabling the agent to perceive screenshots and issue mouse and keyboard actions. A UI automation process was introduced, with actions formalized as function calls and organized into planning, action, and reflect loops. Within the acting and reflecting…
-
Finetuning LLMs for Automatic Form Interaction on Web-Browser in Selenium Testing Framework
ref: https://arxiv.org/pdf/2511.15168 Summary Trained a new LLM to understand web form (HTML code) and generate reliable Selenium script for webpage testing. Differ to WebVoyager, which rely on visual navigation (UI Agent). This method model UI automation to a deterministic code generation working on UI/UX. While this improve execution, the approach still suffer typical code generation failure.…
-
The Iceberg Index: Measuring Skills-centered Exposure in the AI Economy
ref: https://arxiv.org/pdf/2510.25137 Summary Performed a workforce “digital twin” simulation on human capabilities overlap with AI. Existing workforce metrics does not work on AI assisted task/skill. A newly metric is introduce to identify task/skill correlate to wages. While tech role (programmer, data science & program manager) already disputed, repetitive cognitive and administrative work remain largely invisible.
