
ref: https://arxiv.org/pdf/2601.04742
Summary
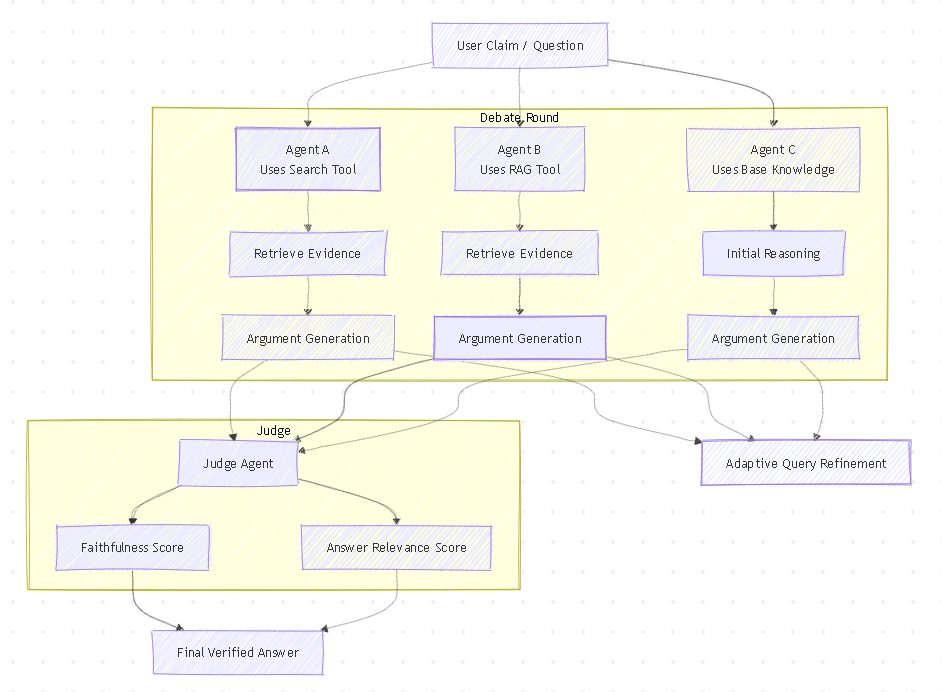
The team studied several methods to improve LLM accuracy and combined the strongest ideas to build Tool-MAD. The system uses evolving AI debaters that run new searches in every round, refining queries based on the discussion to gather better evidence over time. A judge agent then evaluates the arguments using faithfulness and relevance scores to select the most supported answer. Results show that when AI updates its search like a human researcher, accuracy improves (up to 5.5%) compared to relying on a single retrieval step.
This approach may resemble the architectural foundation to Ralph Wiggum Loop and Clawdbot. Integrating this capabilities into chatbot could offer a faster path to improving accuracy than fully redesigning workflows.
Query Selection prompt
You are a participant in a fact-checking debate. Our goal is to reach aconsensus with an accurate answer. You are an agent utilizing RAG.You are in query select page, you can choose change query or continue useyour query.Only output the query, and wrap it in square brackets like this: [your queryhere]. Do not include anything else.Other debaters answer: {other_answer}Before you used query : {used_query}Claim : {prompt}
N Round’s Debate prompt
If the claim is correct, you must first explain why it is correct based on thedocument, then output **SUPPORTS**.If the claim is incorrect, you must first explain why it is incorrect based onthe document, then output **REFUTES**.If the evidence is unclear or inconsistent, you must first explain theuncertainty, then output **NOT ENOUGH INFO**.Your final answer (**SUPPORTS**, **REFUTES**, or **NOT ENOUGHINFO**) must appear on the last line only, after your reasoning.Claim : {prompt}Other debaters answer : {other_answer}Document : {search_result}
Judge prompt
You are the judge for the fact-checking debate. This is the final round of thedebate. If no consensus has been reached, you must determine the correctanswerThe faithfulness score measures how accurately the agent's answer reflectsthe retrieved documents, while the answer relevancy score indicates howwell the answer addresses the original question.A higher score means better alignment and greater reliabilityBased on the debate history and faithfulness and answer relevancy score,please determine the correctness of the claim as follows:if the claim is correct, output **SUPPORTS**if the claim is incorrect, output **REFUTES**if it is uncertain whether the claim is correct, output **NOT ENOUGHINFO**Debate History : {debate_history}RAG Agent's Faithfullness Score : {rag_faithfullness / 3}RAG Agent's Relevancy Score : {rag_answer_relevance / 3Search Agent's Faithfullness Score : {search_faithfullness / 3}Search Agent's Relevancy Score : {search_answer__relevance / 3}Claim : {prompt}

Leave a comment