

dataset: https://archive.ics.uci.edu/dataset/53/iris
While scrolling through YouTube, I came across this video:
https://www.youtube.com/watch?v=MdOCu2Gr-0g
It explores Fibonacci numbers, which sparked a thought—could I experiment with them in a unique way, perhaps using the Iris dataset?
First, let’s create a sequence of Fibonacci numbers.
fibonacci_sequence = []
a, b = 0, 1
n = 20
for i in range(n):
fibonacci_sequence.append(a)
a, b = b, a + bResult:

Next, we create a function that returns the largest Fibonacci number closest to a given value.
def largest_fib_leq(num):
larger_fibs = [fib for fib in fibonacci_sequence if fib <= num]
return max(larger_fibs) if larger_fibs else NoneTransform the DataFrame using the function, along with other as needed.
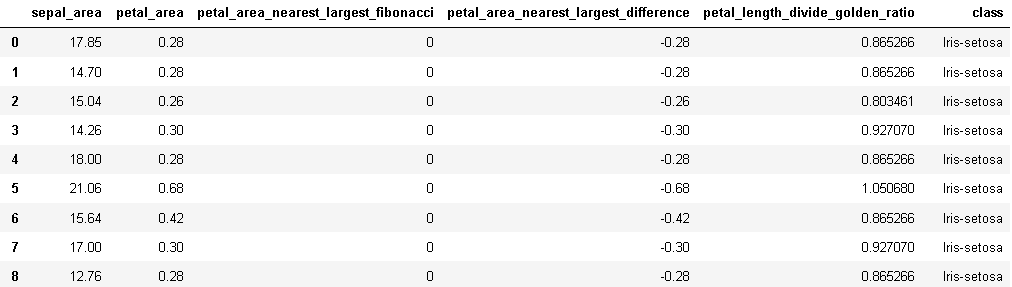
df["sepal_area"] = df["sepal_length"] * df["sepal_width"]
df["petal_area"] = df["petal_length"] * df["petal_width"]
df['petal_area_nearest_largest_fibonacci'] = df['petal_area'].apply(lambda x: largest_fib_leq(x))
df["petal_area_nearest_largest_difference"] = df['petal_area_nearest_largest_fibonacci'] - df['petal_area']
df["petal_length_divide_golden_ratio"] = df["petal_length"] / 1.618Result:
Run a decision tree model in Dataiku, or use sklearn if you’re willing to put in the effort to code it yourself.
Result:

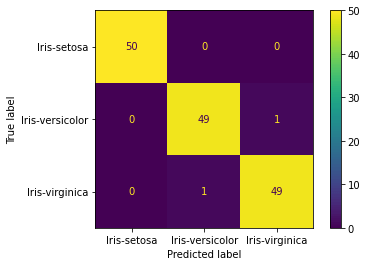
Convert the decision tree into if-else statement.
df['class_predicted'] = ""
for index, row in df.iterrows():
if row['petal_length_divide_golden_ratio'] <= 1.51:
df.at[index, 'class_predicted'] = 'Iris-setosa'
continue
if row['petal_length_divide_golden_ratio'] > 1.51 and row['petal_area'] <= 7.43:
df.at[index, 'class_predicted'] = 'Iris-versicolor'
continue
if row['petal_length_divide_golden_ratio'] > 1.51 and row['petal_area'] > 7.43 and row['petal_area'] <= 8.73 and row['sepal_area'] > 18.44:
df.at[index, 'class_predicted'] = 'Iris-versicolor'
continue
if row['petal_length_divide_golden_ratio'] > 1.51 and row['petal_area'] > 7.43 and row['petal_area'] <= 8.73 and row['sepal_area'] <= 18.44 and row['petal_area_nearest_largest_difference'] > -0.40:
df.at[index, 'class_predicted'] = 'Iris-versicolor'
continue
df.at[index, 'class_predicted'] = 'Iris-virginica'And the result? Voilà! 100% classification achieved!

Edit. Of course, the classic method of multiplication!
df['petal_area_d_sepal_area_m_petal_length'] = df["petal_area"] / df["sepal_area"] * df["petal_length"]
df['class_predicted'] = ""
for index, row in df.iterrows():
if row['petal_area_d_sepal_area_m_petal_length'] <= 0.43:
df.at[index, 'class_predicted'] = 'Iris-setosa'
continue
if row['petal_area_d_sepal_area_m_petal_length'] > 0.43 and row['petal_area_d_sepal_area_m_petal_length'] > 2.30:
df.at[index, 'class_predicted'] = 'Iris-virginica'
continue
df.at[index, 'class_predicted'] = 'Iris-versicolor'Result:
Thank you for reading! Feel free to share your thoughts or opinions—I’d love to discuss them with you!

Leave a comment