
Perks!
install.packages("dplyr")
library(dplyr)Add “dplyr” package to enable following function
select()filter()mutate()arrange()summarize()sample()
select(variable_name, column_name) → similar like SQL select, can perform column alias, range column name, start/end with column name and exclude column.
df=data.frame( matrix(seq(1, 12), 4, 3) )
select( df, -X1 )
select( df, X2:X3 )
select( df, X2, X3 )
select( df, c("X2", "X3") )Result:
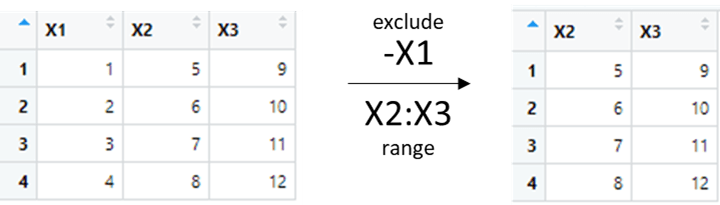
filter(variable_name, condition) → single or multiple logical condition; similar to subset().
df=data.frame( matrix(seq(1, 12), 4, 3) )
filter( df, X1==1 )
filter( df, X1==1 & X2==5 )
filter( df, X1==1 | X2==4 )Result:

mutate(variable_name, column_name) → create, edit or delete column (fill value with NULL).
df=data.frame( matrix(seq(1, 12), 4, 3) )
mutate( df, X4=c(1,2,3,4) )Result:

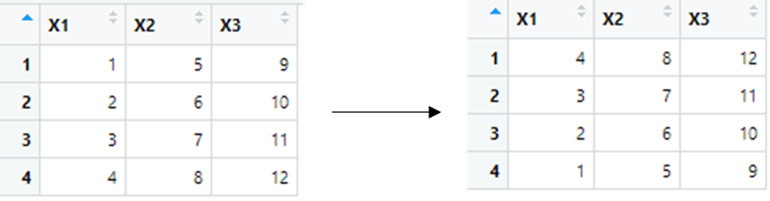
arrange(variable_name, column_name)
df=data.frame( matrix(seq(1, 12), 4, 3) )
arrange( df, desc(x1) )Result:
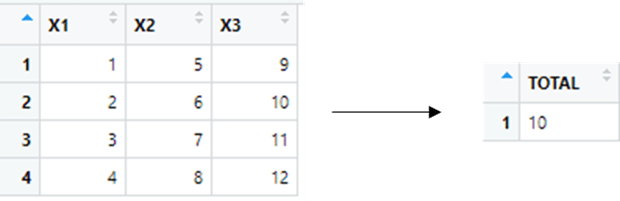
summarize(variable_name, aggregation)
df=data.frame( matrix(seq(1, 12), 4, 3) )
summarize( df, TOTAL=sum(X1) )Result:
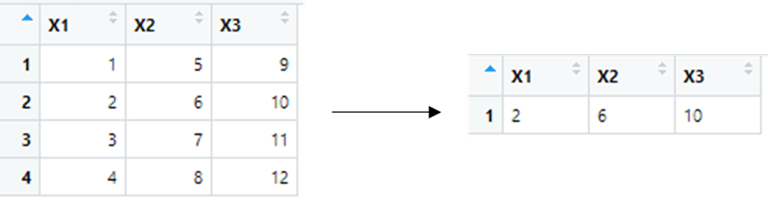
sample_n/sample_frac(variable_name, value)
df=data.frame( matrix(seq(1, 12), 4, 3) )
sample_n( df, 1 )
sample_frac( df, .3 )Result:

Leave a comment