
5 Daemon
“Daemon” that sound like demon, is the background service that not initiated by user.
HDFS
- (Slave)……………….. Data Node
- …………….(Master) Name Node
- …………….(Master) Secondary Name Node (Backup)
Map Reduce
- (Slave)……………….. Task Tracker
- …………….(Master) Job Tracker
Hadoop is distributed storage and processing.
It only means the data node (storage & processing), not for name node; Name node (master) must be high availability hardware (expensive); Secondary name node come in to make name node HA. Treat it as MSSQL Log, data is write into log and later commit. if something happen, database recover from last log.
Not all slave can talk to master, only task tracker reply to job tracker when the task is complete. Slave talk to each other normally happen like N10 down, N11/24 has data to rebuild N10, thus N11/12 pass data when rebuilding N10.
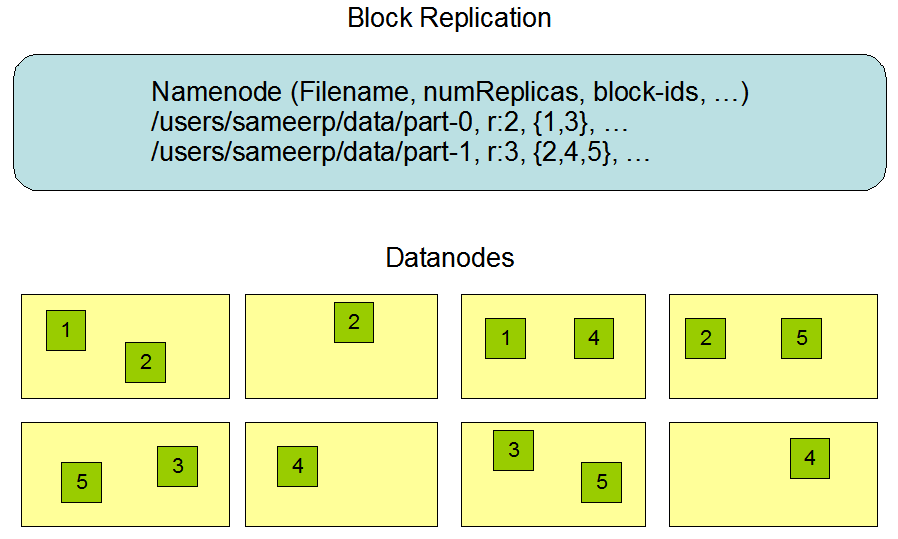
Name Node handle distribution
Name node store the pointer of data file location in data node. If the data node is down, it will redirect the data ingestion to another data node.
HDFS Block Placement Strategy

Leave a comment